숭실대학교 하석재 교수님의 2022-1학기 컴퓨터 구조 강의를 정리 및 재구성했다.
[어셈블리 명령어]
- 기계어와 일대일로 대응이 되는 컴퓨터 프로그래밍의 low-level 언어이다.
-Assembler : 어셈블리 언어를 기계어로 변환해주는 기능을 하는 장치.
- 아키텍쳐의 차이에 따라 어셈블리 명령어가 다르다.
-CISC 아키텍쳐 (Intel x86/ x86-64) vs RISC 아키텍쳐 -MIPS/ARM/RISC-V
앞으로의 내용에는 MIPS기준으로 쓰일 예정이다.
-명령어의 표현 방식을 이해를 하면 컴퓨터의 내장 프로그램 개념(stored-program concept)을 이해할 수 있다.
-내장 프로그램 개념: 여러 종류의 데이터와 명령어를 메모리에 숫자로 저장할 수 있다는 개념 (ex 앞에서 설명한 폰 노이만, 하버드 아키텍쳐가 그 예시이다.)
[명령어의 종류 및 형태]
[종류]
- 레지스터/ 메모리 번지(주소)에 데이터를 로드하는 명령어
-ex)메모리 100번지에 있는 값을 첫번째 레지스터에 저장하기.
-레지스터와 메모리 주소에서의 읽기/쓰기(덮어쓰기) 명령어
- 산술 연산 명령어 (더하기, 빼기)
- 논리 연산 명령어 (and, or, nor, shift)
-분기 명령어 (조건, 무조건)
[형태]
*add a,b,c : b와 c를 더해서 a에 저장.
- a,b,c는 operand(인자)라고 하며, mips 계열의 operand 개수는 주로 3개이다.
[Word / Word Alignment]
-워드(word)
-CPU가 한 사이클(틱)에 처리하는 데이터 크기
-보통 8/16/32/64비트 중 하나이다. 현재는 64비트가 주류이다.
-128비트는 비용적인 제약으로 인해 개발되지 않는다.
-뱅크 (bank)
-램의 데이터 출력 핀 개수와 워드 값을 맞추기 위한 개념.
- 한 개의 메모리의 출력이 8비트인 경우 32비트 워드 값과 맞추려면 램 4개가 필요함.
-SIMM(single in-line memory module) vs DIMM (double in-line memory module)
- 모듈의 한 면만 사용할 수 있냐, 양면을 다 사용할 수 있냐의 차이. 워드값을 맞추기 위해 simm or dimm중에 선택하여 사용할 수 있다.
- 채널(channel)
-메모리 채널은 메모리와 CPU의 캐시 간에 데이터 전달 통로이며, 메모리 컨트롤러의 워드값을 CPU보다 크게 만들어 "메모리 대역폭(bandwidth)를 크게 늘리는 기술"이다.
-ex)듀얼/트리플/쿼드 채널 -> 램 2,3,4개 꽂는 것이 램 1개 쓰는 것보다 메모리 대역폭이 크다.
-정렬제약(alignment restriction)
- 데이터를 워드크기(4바이트 기준)에 맞춰 정렬해서 저장하는 기법
-ex) 컴퓨터는 3바이트 컬러값(24비트)를 사용해서 1600만 가지 색상을 표현하는데, 3바이트는 워드값인 4바이트와 다르다. 그대로 저장하면 특정한 점의 컬러값을 읽는데 메모리 접근을 2번 이상 해야 하는 경우가 생긴다.
=>속도 향상( 1바이트의 저장용량을 포기) vs 저장 효율(저장 용량을 포기하지 않고) 둘 중에 선택권이 생긴다.
=>버리는 1바이트를 다른 용도로 사용할 수 도 있다.(ex)투명도를 나타내는 내용)
[MIPS의 특징]
- 명령어의 오퍼랜드의 개수가 3개인 경우가 대부분이며 이로 인해 하드웨어가 단순해진다.
- 레지스터는 32개
-메모리를 최대 1GB을 지원한다.(2 ^30)
-워드 값은 4바이트
cf)Windows 운영체제에서는 word는 2바이트, DWORD는 4바이트이다. (legacy)
-숫자의 signed/unsigned 지원
-메모리 word(4바이트), half word(2바이트), byte 접근 지원
[메모리 접근 주소 계산]
-메모리접근 주소는 베이스 레지스터 + 변위
-변위(offset): 데이터 전송 명령어의 상수 부분
-베이스 레지스터(base register): 계산을 위해 더해지는 레지스터
-cf) pc register : 다음에 실행될 명령어의 주소를 가지고 있어 실행할 기계어 코드의 위치를 지정하는 레지스터.
[리틀엔디안/ 빅엔디안]
-엔디안 : 컴퓨터의 메모리와 같은 1차원의 공간에 여러 개의 연속된 대상을 배열하는 방법.
[빅엔디안]

-높은 메모리 번지에 낮은 숫자를 저장한다.
[리틀엔디안]
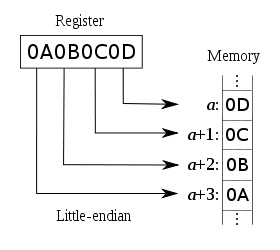
- 높은 메모리에 높은 숫자를 저장한다.
[비교]

[엔디안 저장방식의 예시]
-빅엔디안은 최상위 비트(MSB)부터 차례로, 리틀엔디안은 최하위 비트(LSB)붜 차례로 저장이 된다.
[레지스터 vs 메모리]
- 속도는 레지스터가 훨씬 빠르며, 개수는 작다.
[부호있는 수 (signed vs unsigned)
-2의 보수: 음수를 표현할 때 1의 보수(0->1, 1->0 변환)에 1을 더한 수
-부호가 없으면 더 큰 수를 표현할 수 있다.
-1바이트로 0~255(unsigned) -128 ~ 127(signed)
-부호 확장(Signed Extension)
-16비트 정수에서 32비트 정수로 변환할 때, 최상위 비트 값을 빈 곳에 채운다. (음수는 1, 양수는 0)
-대부분의 고수준의 언어는 signed/ unsigned를 지정할 수 있다(c/c++/python)
cf) java는 signed만 존재한다.
[명령어 형식(Instruction format)]

-총 32bit
-opcode(6)/rs(5)/rt(5)/rd(5)/shamt(5)/funct(6)
-R타입(기본 레지스터에서 해석되는 방법) vs I타입(직접 주소를 지정하는 방법)
-길이는 동일하다.
[명령어]
-논리 연산/ 시프트(shift)
-비트 AND/OR/NOR/NOT
-비트 마스크(bit mask) : 특정 비트만 뽑아내는 방법
ex)1과 or연산을 했을때는 연산 대상과 상관없이 1이, 0과 and 연산을 했을 때는 0이 나온다.
-AND/OR/NOT/NOR/NAND - NAND/NOR 중 하나로 나머지 모든 연산이 표현 가능하다.
-실제 반도체에서는 NAND나 NOR를 기본 소자로 모든 회로를 표현 할 수 있다.
-분기문
-조건부(if에 해당) / 무조건(loop에 해당)
-case/ switch
-점프하려는 주소들을 테이블화 시켜서 실행할 수 있다.
[함수(프로시져) 지원]
- 함수(function) vs 프로시져(procedure)/서브루틴(subroutine)
-함수는 리턴값이 존재, 프로시져와 서브루틴은 리턴값이 존재하지 않는다.
-c/c++/c#/java에서는 프로시져 없이 모두 함수(리턴값이 없는 경우에는 리턴값을 void로 설정)
-jal(jump and link)
-함수의 복귀 주소를 가지는 어셈블리 명령어이다. (jump후 복귀주소로 link)
-PC(Program Counter) 레지스터 -현재위치: jump시에 저장 되어있어야한다. .
-함수를 호출했을때의 리턴 주소/ 인자 리스트/ 리턴값을 activation record라 하며 스택 포인터로 저장한다.
-스택 vs 힙
-함수의 인자/리턴값은 스택에 저장을 한 후, 호출이 끝나면 사라진다.
- 상대적으로 오래남는 값(전역변수 등)은 힙에 저장한다.
-메모리 누출(Memory Leak)
-할당받은 메모리를 돌려주지 않고 리턴을 하는 경우 문제가 생긴다.(c/c++)
-java/c#에서는 Garbage Collection을 이용한다.
-C/C++에서의 메모리 관련 문제점
-버퍼 오버플로우(Buffer Overflow) 해킹에 취약하다.
-인자를 약속된 길이보다 긴 값을 기록해서 리턴값을 덮어쓴다. 이로 인해 리턴주소의 조작이 일어난다.
- 경계값 검사를 하지 않는 것을 악용한다. java는 경계값 검사를 하기 때문에 취약점이 없다.
[문자/문자열]
-ASCII
-숫자를 문자(알파벳+특수문자 등)로 해석
-1바이트 하용/ 한글은 2바이트로 표현
-완성형
-문자열
-문자열 앞에 길이를 표시한다.
-구조체 형태로 길이/문자를 표현한다.
-문자열의 끝을 표현하는 특수문자가 존재한다.(Escape 처리), C/C++은 null을 마지막에 붙임.
-유니코드
-UTF-16
-모든 글자를 2바이트로 표현한다. (알파벳 포함)
-65000자 이상의 글자를 표현 가능하다.
-UTF-8
-1~4바이트 멀티바이트의 유니코드이며 유니코드와의 호환성을 고려했다.
-현재 주류이며, 주로 웹에서 많이 사용이 된다.
-대역마다 2~4바이트로 표현한다.(한글은 3바이트)
cf)Mysql은 3바이트 UTF-8과 4바이트 UTF8(MySQL 8지원)이 있음.
-문자열 복사
-strcpy(경계값 취약점이 존재한다.) vs strncpy(지정된 길이만큼만 복사를 하며, 취약점이 존재하지 않는다.)
[MIPS의 주소 지정방식]
-일반 분기의 주소필드는 26비트이며 하나의 프로그램은 256(2^26)mb이상을 지원하지 않는다. 하지만 메모리는 1GB(2^30)까지 지원한다.
-조건부 분기는 16비트 주소필드이며, PC값에 16비트 offset을 통해 간접지정한다.
-인텔 X86
-모드 별로 지원하는 메모리의 크기가 다르다. 가상 X86모드는 1MB(640KB)를 지원하고, 보호모드는 램 크기에 맞게 모두 지원을 한다. 하지만, 가상 X86과의 호환성이 맞지 않는다.
-예전 C언어의 Far/Near포인터의 경우에도 64kb이내로 지원되기 때문에 사용이 됐다.
-Legacy와 관련이 깊다. 램의 크기가 지금정도의 크기까지 커질 것이라고 예상을 하지 못했다.
[동기화]
-여러개의 태스크(Task) 또는 프로세스(Process)가 동시에 동작할 때 데이터의 접근제어를 안전하게 만드는 기법이다.
[인터프리터]
-vs 컴파일러
-인터프리터는 느리지만 바로 실행가능하기 때문에, 개발과정에서 장점이다.
-일반적으로 컴파일러가 빠르지만, 프로그램 코드가 한 줄만 변경되어도 새로 컴파일해야한다.
또한, 프로그램이 커지면 컴파일 시간이 따라서 증가한다.
-java는 컴파일 언어지만 결과물인 클래스 파일(.class)을 실행할 때는 인터프리팅 방식(JVM)으로 실행한다.
-python/ javascript는 인터프리터 언어이다.
-인터프리터 언어를 빠르게 만드는 기술
[JIT(Just in-Time)컴파일러]
-실행 시 컴파일 방식이며, 일반적인 컴파일러 언어는 실행하기 전에 컴파일을 해야하지만 JIT방식은 프로그램을 실행하면 그 때 코드를 실행한다.
-컴파일이 종료되면 실행은 빠르다.
-실행할 때마다 컴파일을 해야한다.
-java의 핫스팟 VM에 적용이 되며, 안드로이드 4.x까지 사용하던 Dalvik VM에서 적용된다.
[AOT(Ahead-of-Time)컴파일러]
-프로그램(앱)을 설치할 때, 미리 컴파일을 진행하는 방식이며 설치할 때 시간이 많이 걸린다는 단점이 있다.
-안드로이드 5이후에 적용된 ART VM에서 적용이 된다.
'컴퓨터 구조' 카테고리의 다른 글
| [컴퓨터 구조] 프로세서 (0) | 2022.08.28 |
|---|---|
| [컴퓨터 구조] 컴퓨터 연산 (0) | 2022.08.26 |
| [컴퓨터 구조] 성능 평가 (0) | 2022.08.23 |
| [컴퓨터구조] 컴퓨터 추상화 (0) | 2022.08.23 |
| [컴퓨터 구조] 컴퓨터 구조 기초 (0) | 2022.08.21 |