문제 상황
현재 진행하고 있는 클러버(clubber) 프로젝트에서는 카테고리 값들이 많은데, 이러한 값들을 별도의 테이블로 분리해서 관리를 해야할지 고민이 많았다. 대표적인 항목으로는 다음과 같다.
- 중앙 동아리 분과 (교양분과, 연행예술분과 등 7개)
- 소모임 소속 학과 및 단과대 (학과 약 20개 , 단과대 약 8개)
- 동아리 리뷰 키워드 항목 5개 (회비가 적당, 커리어에 도움 등 5개)
- 동아리 분류 해시 태그 (개발, 요리, 시사 등 약 10개)
리팩토링 이전에는 프론트엔드와 백엔드 간의 요청, 응답은 문자열로 주고 받았고 (ex: 해시태그가 요리인 동아리 조회)
별도의 테이블로 저장하지 않았기 때문에 프런트엔드에서 문자열로 하드코딩해서 넘겨주기로 했다.
코드 테이블 (DB)
별도의 DB 테이블로 분리를 하지 않았던 이유는 다음과 같다.
1) 자주 바뀌지 않는다
예를 들어 리뷰를 작성 할 때 키워드는 무조건 5개로 정해져 있는 상태로 작성하기로 하였고, 대학교의 학과나 단과대의 경우 사용자의 응답이 아니라 외부 이벤트(학과 추가 같은)에 의해 발생할 뿐이다. (제작년에 한번 일어나긴했다)

2) 구성된 데이터 값의 종류(DB 컬럼)이 많지 않다.
1. code(코드명) - 식별자, 주로 API 통신용
2. title(주로 화면에서 보여질 이름)
정도가 있고, 확장될 일이 거의 없었다. (추후 확장된 경우가 있었는데 이는 글 뒤에서 설명한다.)
3) 테이블 조인 연산이 필요하다.
만약 DB 테이블로 구현하게 된다면 조인 연산이 추가된다. 특히, 동아리의 경우 현재 서비스에서 조회되는 경우가 특히나 많은데, 코드 테이블이 분과, 학과, 단과대까지 있기 때문에 코드 테이블과 조인하는 연산이 더욱 많아질 것이다.
해결
Enum 적용
Enum을 활용한 근거는 다음과 같다.
1. 필요한 원소를 컴파일 타임에 충분히 알 수 있다.
2. 만약 수정사항(데이터 추가 등)이 있다해도, 코드를 수정 후 재배포하여 충분히 대응이 가능하다고 생각했다.(CI/CD를 구축해두었다.)
3. Enum 클래스의 장점을 적극 활용할 수 있다. (타입 안정성 등)
1) 구현
1. EnumMapperType
카테고리 데이터를 추상화한 공통 인터페이스이다. 각 카테고리 데이터는 앞에서 언급한 code, title을 반환하기 때문에 메서드에 getter 함수를 선언했다. Enum은 클래스 상속이 불가능하기 때문에, 별도의 인터페이스를 정의하여 통일성을 높였다.

2. Enum (구현체)
각 Enum 클래스에서 code, title 반환(getter) 함수를 구현한다.

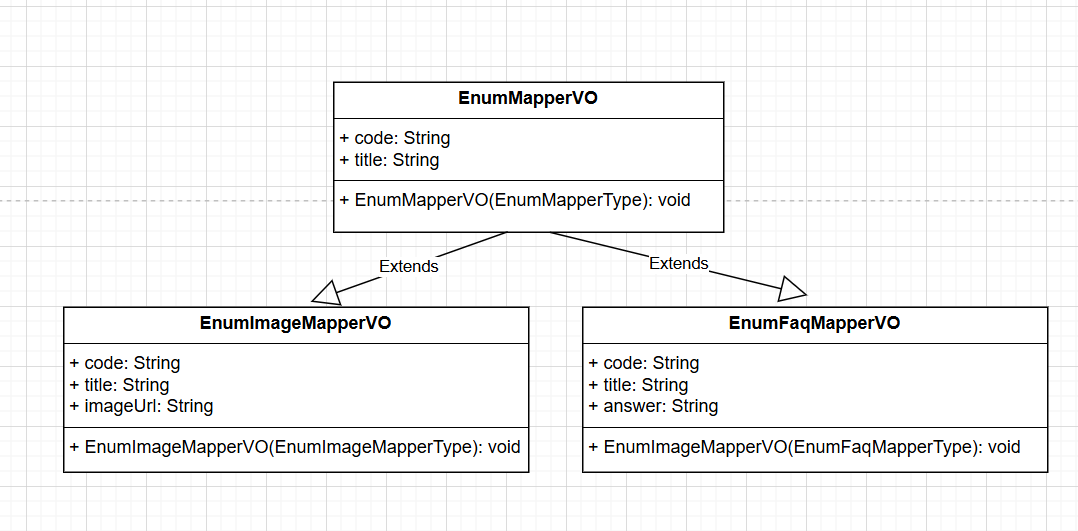
3. EnumMapperVO
실제 데이터 값을 담는 VO 클래스이다. 인터페이스를 생성자의 인자 타입으로 정의하였고, 이를 구현하는 Enum 구현체에서 getter을 호출하여 매핑한다.

4. EnumMapper

특정 Enum 클래스와 관련된 값들을 저장, 관리할 수 있는 클래스이다.
[List<EnumMapperValue> factory]
- Enum 타입별 VO 값들을 관리한다.
- Map 자료구조로 구현했다.
1. Key : 문자열 클래스명
2. Value : VO 리스트
[toEnumValues()]
Enum 클래스 타입을 인자로 넘기면 원소들의 객체를 생성한 후, 앞에서 구현한 EnumMapperVO 생성(매핑) 후 factory 변수에 리스트 형식으로 저장된다.
5. EnumConfig

매번 EnumMapper 원소 객체들이 생성되는 것을 막고자 Spring Bean으로 등록했다.
결과
- API를 호출하여 키워드 목록을 반환시 결과 화면이다.


2) 확장
code, title 이외에 다른 값을 더 가지는 카테고리 데이터가 생겼다. 예를 들면, FaQ도 Enum으로 관리하는데 code, title 이외에 answer 필드가 추가적으로 필요하였다. 각 인터페이스에서 반환하는 VO 객체의 클래스 타입 달라지기 때문에, 인터페이스에서 각기 다른 VO를 반환하는 메서드를 추가하였다.

각 Enum에서 일일히 구현해도 되긴 하나, VO 종류 자체가 많진 않아서 인터페이스를 확장하여 별도의 타입을 만들고 default 메서드로 구현하였다. (아무래도 최상위 VO 클래스로 반환하는 경우가 제일 많다.)
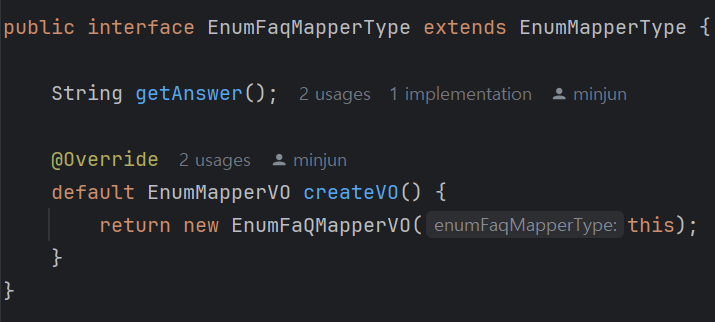


EnumMapper의 List<EnumMapperVO> factory의 경우, 각기 다른 하위타입으로 저장 가능하다. 인터페이스에서 createVO의 반환타입을 실제 반환하는 하위 구체 클래스(EnumFaqMapperVO)가 아니라 가장 상위 클래스인 EnumMapperVO으로 지정했기 때문이다. 컴파일 타임에서 EnumMapperVO로 인식하며, 런타임에 toEnumValues 메서드 호출시 하위 VO 클래스가 생성되어 반환된다. 만약, 반환 타입이 최상위 VO가 아니었다면, 제네릭 타입의 무공변성 때문에 상한 와일드카드를 지정해야했을 것이다.

완성된 인터페이스, 클래스 구조는 대략 다음과 같다.
1) 인터페이스, Enum (구현)

2) VO
결과
faq 목록 조회 API시 하위 VO 클래스에 매핑되어 반환된다.

느낀점
1. Enum 사용 기준
처음부터 Enum으로 관리해야겠다는 생각이 잘 들지 않았던 이유는 카테고리 데이터 중 학과 데이터가 특히 많았기 (약 20여개) 때문이다. 물론, 자주 바뀌지 않더라도 레코드나 컬럼 개수가 너무 많다면 별도의 코드 테이블로 관리하는 것도 괜찮다고 생각한다. 하지만, 그럼에도 Enum으로 관리한 이유는 사용자의 요청 아닌, 외부 이벤트에 의해 변경되고 변경 주기도 길기 때문이었다.
2. 인터페이스 선언의 장점
인터페이스를 선언함으로써 다양한 카테고리 데이터를 EnumMapper 클래스에서 일관되게 관리할 수 있었다. VO 객체 생성시 생성자에서 인터페이스 타입으로 인자를 받고, 인터페이스에서 선언한 메서드(getCode(), getTitle())를 호출하여 통일되게 객체를 생성할 수 있었다. 또한, VO 생성 함수의 반환 타입을 최상위 VO 타입으로 선언하여 각 카테고리 타입에 맞는 VO 객체를 생성할 수 있었다. 이로 인해, 손쉽게 다형성을 이용할 수 있었다고 생각한다.
참고
[Effective Java] 아이템 34. int상수 대신 열거 타입을 사용하라
[Effective Java] 아이템 38. 확장할 수 잇는 열거 타입을 필요하면 인터페이스를 사용하라
'클러버' 카테고리의 다른 글
| [클러버] @Builder을 활용한 Fixture 셋업 개선 (0) | 2025.03.17 |
|---|---|
| [클러버] Java Enum을 활용한 프로젝트 개선기 (3) (0) | 2025.02.13 |
| [클러버] 운영을 위한 초기 인프라 구축 과정 (0) | 2025.02.12 |
| [클러버] Java Enum을 활용한 프로젝트 개선기 (2) (0) | 2024.07.07 |
| [클러버] JPA 상속 매핑에 대한 고민 (0) | 2024.06.23 |